
Wow! #QualiService could be a great resource!
It wasn't obvious to me how to find the transcripts for these doctor-patient interaction data from 4 countries, but if such transcripts are accessible, that's GREAT!
.")
Wow! #QualiService could be a great resource!
It wasn't obvious to me how to find the transcripts for these doctor-patient interaction data from 4 countries, but if such transcripts are accessible, that's GREAT!
 Want to analyze text from the EU public consultations? EU public consultations are a way in which the EU invites the broader public to publicly comment on upcoming legislation.
Want to analyze text from the EU public consultations? EU public consultations are a way in which the EU invites the broader public to publicly comment on upcoming legislation.

 I just published a first version of a Python package {eu-consultations} to scrape and extract text from the EU website:
I just published a first version of a Python package {eu-consultations} to scrape and extract text from the EU website:
https://github.com/marioangst/eu_consultations
- download consultation data as displayed on the EU's frontend into a validated form
- download associated files (this is the hard part about analysing this data - lots of feedback is in .docx and .pdf files)
- extract text from the files using docling and attach to feedback
You get all data in validated form and possibly stored in huge (sorry for that) JSON files ;).
This package is part of an analysis project on feedback the EU has received via the public consultation process on digital policy we plan to present later this year, but I thought let's make some of the tools we use open source way earlier already.

AI-Powered Document Chat and Summarization Tool
Interact with documents, summarize, and get answers using AI.
https://zurl.co/wAly2
https://zurl.co/znKj5
#AI #DocumentChat #Summarization #ResearchTools #MultidocChat #LightPDF #AItools #DocumentInteraction #TextAnalysis #ResearchSupport #SmartSummarization #AcademicAI #InformationExtraction #ChatWithDocuments #DataInsights
Useful contribution to discussions in this area, for sure! The results highlight "whether an automated approach that would still require micromanaging and adjusting several variables by the human researcher would, in fact, be more efficient an approach compared to the same tasks performed manually by human labour"
Out of Context! Managing the Limitations of Context Windows in #ChatGPT-4o Text Analyses https://doi.org/10.46298/jdmdh.15090 #DigitalHumanities #TextAnalysis #LLM #ArtificialIntelligence #GLAMR

NLP for Data Science: Insights from Text
#NLP #DataScience #TextAnalysis #MachineLearning #DeepLearning #NaturalLanguageProcessing #AI #DataMining #BigData #TextMining #SentimentAnalysis #TopicModeling #WordEmbeddings #DataVisualization

Why Natural Language Processing (NLP ) Is the Future of Data Science
#NLP #DataScience #MachineLearning #AI #BigData #TextAnalysis #DeepLearning #NaturalLanguageProcessing #DataAnalytics #DataMining #LanguageModels #PredictiveAnalytics #ArtificialIntelligence #DataVisualization #DataDriven #TechInnovation #Analytics #SmartTech #FutureOfAI
https://icacedu.com/why-a-natural-language-processing-nlp-is-the-future-of-data-science/

Mastering these core NLP techniques is crucial for any data scientist dealing with text data. From tokenization to language modeling, each method serves a unique purpose in processing, analyzing, and extracting valuable insights from textual information.
#NLP #DataScience #Tokenization #LanguageModeling #TextAnalysis #TextMining #MachineLearning
read more: https://blogulr.com/khushnuma7861/topnlptechniqueseverydatascientistshouldknow-120682

Like we found in “Your Health vs. My Liberty” (https://doi.org/10.1016/j.cognition.2021.104649) Yael Rozenblum et al. found that compliance with #publicHealth guidance correlated with indicators of the perceived threat of a viral pandemic.
Also, relying on #misinformation correlated with reliance on simple (vs. complex) #reasoning.
The free paper: https://doi.org/10.1002/tea.21975
 and compliance (“stance”).")
 predicted compliance (“stance”).")
.")

Have you ever wanted to use a #LLM as one step in a workflow?
We integrated #GPT into the open-source analysis platform #useGalaxy, where you can link GPT to several thousand other tools, add more attachments for analysis and make your research reproducible.
https://galaxyproject.org/news/2024-09-02-chat-gpt/
In our example, we uploaded an audio file and used #Whisper to convert it into text, cut out the moderation, and prompted chatGPT to translate it into German.

 New working paper: "Evaluating Embedding Models for Clustering Italian Political News"
New working paper: "Evaluating Embedding Models for Clustering Italian Political News"
This study compares embedding models for unsupervised clustering of Italian political news shared on Facebook before the 2018 and 2022 elections, aiming to advance NLP methods for political text analysis in non-English languages.
Paper: https://osf.io/preprints/osf/2j9ed
Code & data: https://github.com/fabiogiglietto/Semantic-Clustering-Italian-News
Feedback welcome!
Pycpidr 0.3.0 introduces:
- Dependency-based Idea Density (DEPID)
- DEPID-R
- Custom sentence and token filters for DEPID
github.com/jrrobison1/pycpidr
Just launched: pycpidr 
https://github.com/jrrobison1/pycpidr
Python library to determine the propositional idea density of an English text automatically.
Idea density is a measure of the amount of information conveyed relative to the number of words used. This metric has applications in various fields, including linguistics, cognitive science, and healthcare research.
#Python #Linguistics #psychometrics #NLP #TextAnalysis #OpenSource
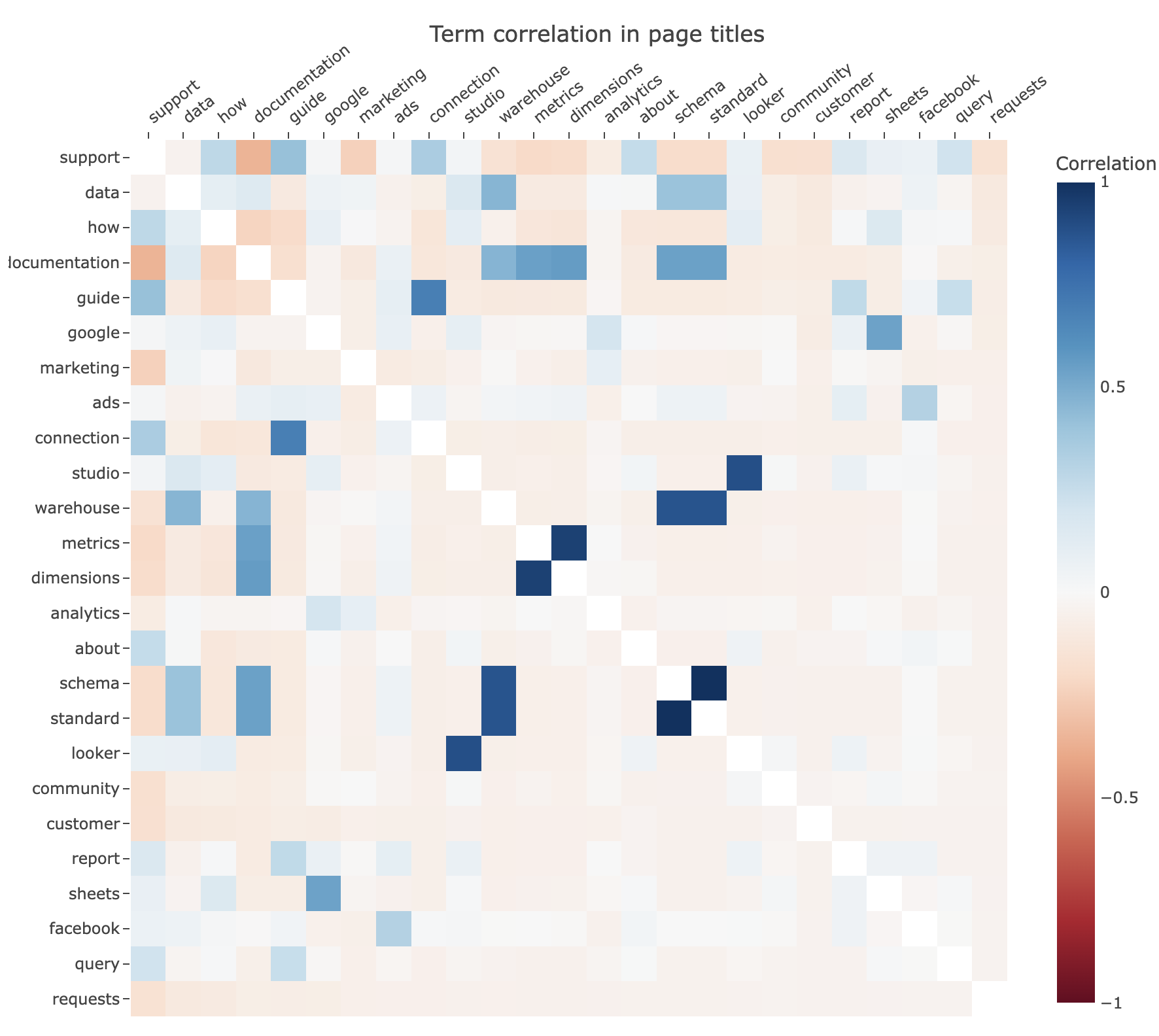
Word co-occurrence matrix/heatmap
How to compute and visualize the correlation between terms that occur together in a list of documents*
*documents: keywords, page titles, product names/descriptions, social media posts, etc.
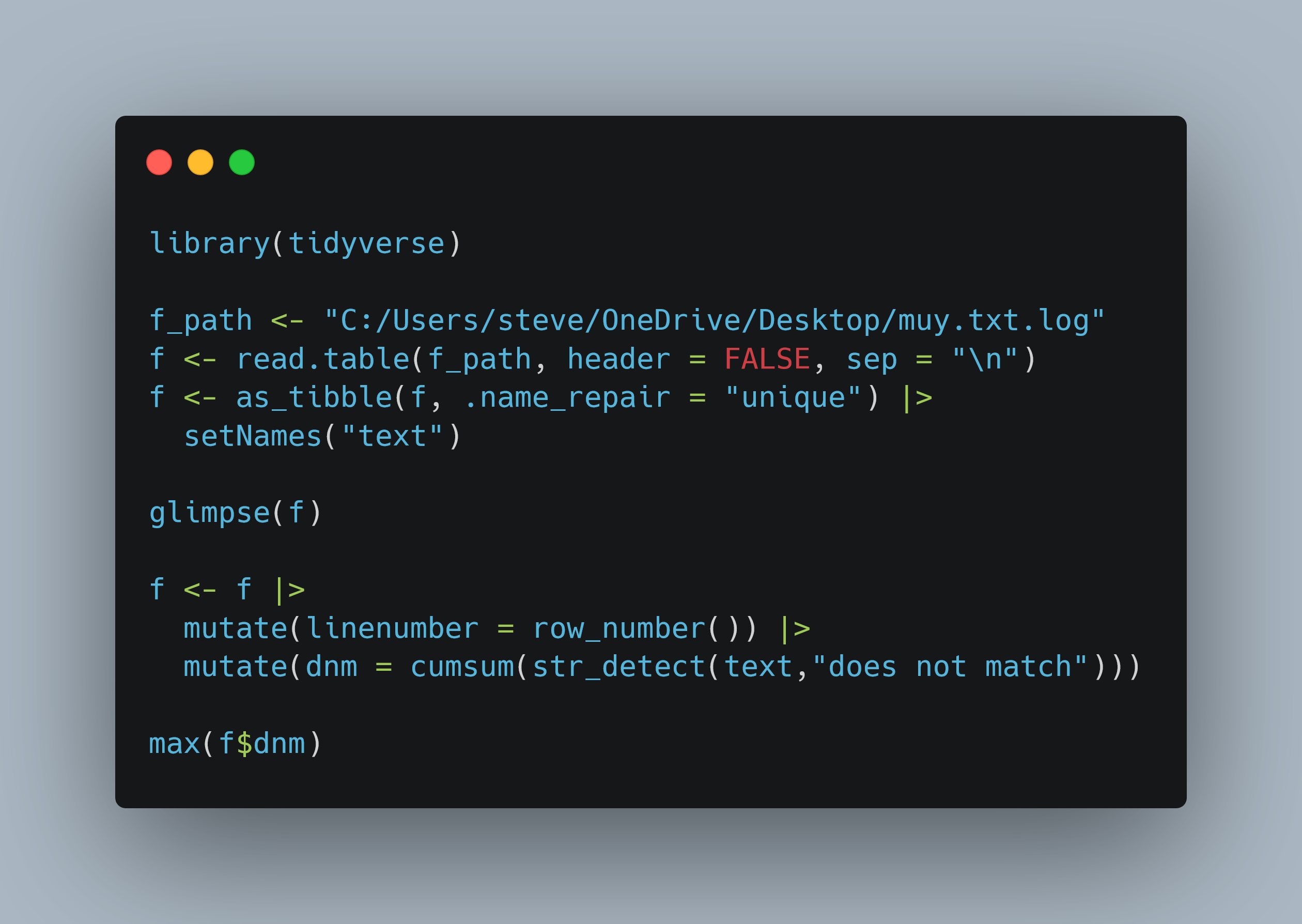
Hi everyone! I recently tackled a common data task using R: counting the occurrences of a specific phrase in a text file. It's a great way to practice text analysis and get familiar with R's powerful tools.
See the attached.
Happy coding! 

The Digital Humanities Team at the University of Vienna and the Ottoman Nature in Travelogues (ONiT) project are hosting a #hackathon focused on analyzing texts, images, and multimodal sources.
Thursday, November 14, 9:00 CET to Friday, November 15, 15:00 CET
https://dh.univie.ac.at/hackathon/
#DigitalHumanities #ComputationalHumanities #TextAnalysis #ImageAnalysis
It was also a methodologically fun paper, combining digitized archival text, Census & survey data, NLP, and panel models.
Email or dm me for a copy! #sociology #textanalysis #rstats
3/3
 Attention Linguistics & Digital Humanities students!
Attention Linguistics & Digital Humanities students! 
Join @janispagel and me for the »Prompting, Evaluation, Interpretation: An Introduction to LLMs in Text Analysis« course at the upcoming Deep Learning for Language Analysis Summer School in Cologne: http://ml-school.uni-koeln.de! 

 Don't miss out – registration is open until June 16th!
Don't miss out – registration is open until June 16th! 
#LLMs #TextAnalysis #NLP #AI #Linguistics #DigitalHumanities #CRETA
Want to learn more about how to use regular expressions in R?
Come join us to learn how to use regular expressions to parse and clean text data on Thursday, June 6th, 5-6pm Eastern Time!
Find the Zoom registration details on our website:
https://rug-at-hdsi.org/upcoming_events/2024-05-06-regex-sarah-hirsch.html

Bias estimation in word embeddings using a Bayesian approach instead of WEAT or MAC. A new paper in Computational Linguistics.

How would you go about creating a filter that blocks posts about things that people hate?
I've thought I could build a text classifier, but it could be hard to train since I'd need to guess whether or not the author hates the thing they are posting about.
I wouldn't want it to become a filter for all current events news, but I suspect that's what it would become.




























