
Veckans avsnitt är här: Kristoffer och Fredrik snackar avamerikanisering och jakten på den perfekta webbstacken. Plus mönster för livet, och kaffe.
Lyssna där poddar finns, eller på https://kodsnack.se/640/

Veckans avsnitt är här: Kristoffer och Fredrik snackar avamerikanisering och jakten på den perfekta webbstacken. Plus mönster för livet, och kaffe.
Lyssna där poddar finns, eller på https://kodsnack.se/640/
Mesmerizing Interlocking Geometric Patterns Produced with Japanese Woodworking
Subtle Lines And White Space
More from White Sands National Park.
https://thecareyadventures.com/blog/subtle-lines-and-white-space/

Some news about the Abstract asset pack series (Repeats, Textures and Tiles).
They are now CC0 1.0.
https://creativecommons.org/publicdomain/zero/1.0/
https://itch.io/blog/928987/license-update-with-abstract-repeats-textures-and-tiles
***
Been thinking about this for a bit, but with Scanned Textures out and wanting to try other things, its the right time to do this. It's been cool seeing what people do and hope this gives more options.
That said, I would still like to do 701 to 800 for textures and 201 to 300/301 to 400 for repeats.

JavaScript Views, the Hard Way – A Pattern for Writing UI

I came across this halftoning idea sometime last week. While the idea was relatively easy to understand and fun to implement, I've spent quite a lot of time trying to make the result look nice.
In each row, the image is split into bins containing roughly the same sum of lightness value. This is nice to implement when the number of lines/bins is a power of 2, so we can recurse with a binary split. Thus the line density varies by average lightness. The problem is that density is considered along the x-axis. If things change a lot between rows, the lines get slanted, so they appear more dense. Here I've included some averaging between neighbouring rows to make thing a bit smoother.
I'm also including a fun glitch from the early tests. The line-density system includes the set of point coordinates and the graph structure (which point is connected to which). What happened here is my generic graph generator that simply finds the nearest neighbours of each point. So in the light areas that are compressed horizontally, the nearest neighbours were left and right.
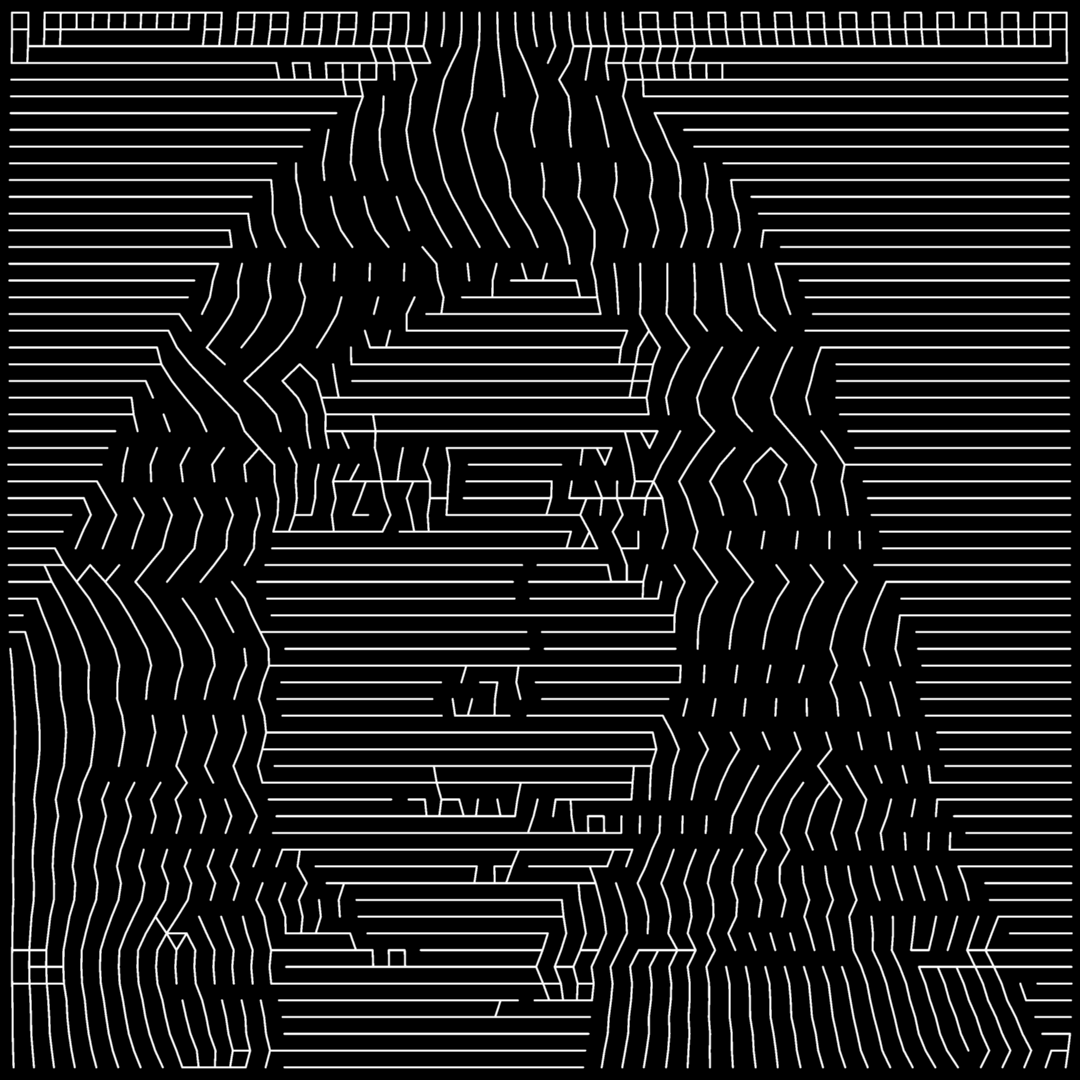
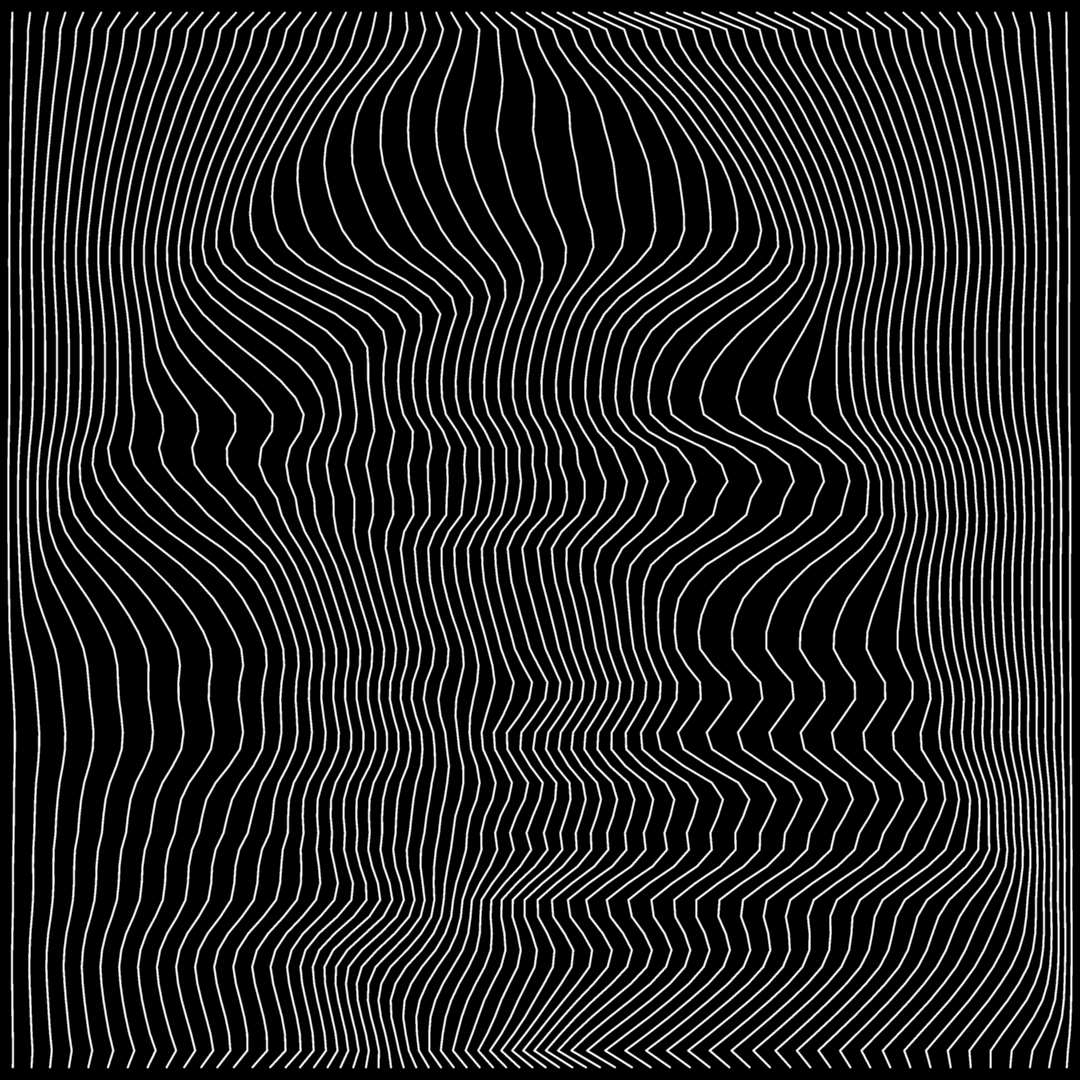
Here's another set of cards with varying patterns, all created with the exact same 4 blended CSS gradients, it's just the stops list `--c` that changes for each card.
So basically, it's again just one `background` + one `background-blend-mode` property.
Live demo on @codepen
https://codepen.io/thebabydino/pen/vYyNyER
 0, #0000 5px 50px;
background:
/* shadows */
repeating-linear-gradient(45deg, var(--s)),
repeating-linear-gradient(-45deg, var(--s)),
/* main pattern */
repeating-linear-gradient(45deg, var(--c)),
repeating-linear-gradient(-45deg, var(--c));
background-blend-mode:
multiply, multiply, lighten
}
.card:nth-child(1) {
--c: #847971 0 10px, #938981 0 20px,
#9e938a 0 30px, #a89c93 0 40px, #bfb6ab 0 50px
}
.card:nth-child(2) {
--c: #333 0 10px, #555 0 20px,
#c55 0 30px, #ccc 0 40px, #eee 0 50px
}")


A bit geeky, I know, but I love this old stone wall in the Yorkhill area of Glasgow. I've got no idea of its age, but it leads down to the former Bishop's Mill, on the banks of the River Kelvin, which was built in 1839.

Want to find patterns in bibliographic metadata? Want to perform bibliographic data science on the history of books?
Then feel free to use this dataset:
Metadata of the "Verzeichnis der im deutschen Sprachraum erschienen Drucke"
https://doi.org/10.5281/zenodo.15167938
This dataset consists exclusively of descriptive metadata of about 750.000 titles, which together form a retrospective German national bibliography of prints 1501-1800.
Landscape Metrics - “R As GIS” Course
--
https://jakubnowosad.com/rgis2025/output/landscape_metrics.html#/title-slide <-- shared presentation
--
#GIS #spatial #mapping #R #tutorial #onlinelearning #presentation #rasters #remotesensing #earthobservation #landscape #metrics #spatialanalysis #spatiotemporal #natural #social #cultural #ecosystems #biodiversity #water #waterquality #usecase #geomorphology #geomorphometry #patterns




I've always found circuit boards aesthetically inspiring, and in recent years this fascination has turned into a number of PCB-styled demos. I think a key inspiration for these has been the "Absolut Intelligence" vodka advert a couple of decades ago.
I haven't done these in a while, but a week or two ago I ran into spanning trees. I noticed that spanning trees of square lattices can make rather nice impersonations of printed circuits, especially when the solder points are only put on leaf points. Cut the tree up into a forest, and it's making even more electrical sense.
Halftoning isn't new to me either, but my existing line-based techniques didn't look nice on the square PCB lattice. It had to be more blocky with exactly horizontal or vertical lines. So for this iteration, I've set each half-edge to have a constant width — a natural evolution of my earlier variants, which were built from half-edge sections. Of course, the solder points follow a similar areal scaling.


Here’s a different view of the mosaic artwork I posted for #SilentSunday. It was just an interesting piece leaning against the wall of a community garden. Viewed here through the garden fence as well as the glass wall (with dot patterns) of a bus shelter nearby.
#photography #streetphotography #mosaic #patterns #abstract

The Mathematics of Crochet
https://hellohartblog.wordpress.com/2015/05/25/the-mathematics-of-crochet/

#Development #Resources
Hacker Laws · Useful laws, principles, and concepts for developers https://ilo.im/1632fe
_____
#Technology #Programming #Coding #Laws #Concepts #Principles #Patterns #WebDev #Frontend #Backend




















 Greg Cocks
Greg Cocks 

