
Stylometry… That’s exactly what it looks like:
you i the a to and that in of it me is this what no on your yeah don't my do…
and so on! Especially if you’re working with movie dialogues

#DHSpringSchool #stylometry

Stylometry… That’s exactly what it looks like:
you i the a to and that in of it me is this what no on your yeah don't my do…
and so on! Especially if you’re working with movie dialogues
#DHSpringSchool #stylometry
Jan Rybicki: You can count many things in films—like dead bodies
 That alone can be a good proxy for genre.
That alone can be a good proxy for genre.
If there’s one, it’s a love story that ends badly
If there are two, it’s a love story that ends even worse
Three to six? A crime story 

A hundred? That’s Rambo
#DHSpringSchool #Stylometry #DigitalHumanities

“Much of what I'll show you will be the colourful pictures of my own failures” — Jan Rybicki (Uniwersytet Jagielloński), in his usual manner, delivers a witty & extremely educational lecture on #Stylometry and #DistantReading in Film after an obligatory bit of ironic self-humiliation  #DHSpringSchool
#DHSpringSchool

Reminder for those who may not realize this, but #Stylometry is kind of an insane field of study, and you can be uniquely identified based on your writing style alone.
This has, in the past, been applied to open source developers and programming code too, and it was found that using stylometry techniques you can identify the author of a compiled binary based on their open source code style ~78% of the time
https://arxiv.org/pdf/1512.08546v1
There are some techniques to avoid this luckily, which involve fairly basic changes to your writing style and structure that can very effectively anonymize things again:
https://en.wikipedia.org/wiki/Adversarial_stylometry
In unserem #StabiLab gibt es Digital Humanities zum Ausprobieren! Am Dienstag, den 21. Januar, lernt ihr bei uns, wie ihr mit dem Tool #Stylo Literatur erforschen könnt  http://sbb.berlin/59m32
http://sbb.berlin/59m32
“Mosin also told the BBC about an incident where Abaturov’s grandmother came to the university to demand an explanation for why her grandson was given a ‘B’ instead of an ‘A.’” #wikipedia #stylometry

Later today at #CHR2024, we are going to present our work on #Multilingual #Stylometry!
We isolated the influence of #language on #authorship #attribution #accuracy by translating multiple #corpora into each others' languages while keeping #corpus composition stable.
Interactive showcase: https://showcases.clsinfra.io/stylometry
Full paper: https://ceur-ws.org/Vol-3834/paper9.pdf
This work was developed within the @CLSinfra project in #Trier, #Krakow and #Prague with Artjoms Šeļa, Evgeniia Fileva and Julia Dudar.

Agapitos and van Cranenburgh use computational #stylometry to show that while 'Octavia' and 'Hercules Oetaeus' were largely written by #Seneca, a closer analysis of the text segments reveals signs of mixed #authorship. https://doi.org/10.48694/jcls.3919 #CLS #CCLS24 #Classics #AuthorshipVerification
Look what landed on my doorstep  The book is also available #OpenAccess online at #heiUP: https://heiup.uni-heidelberg.de/catalog/book/1157 and I would like to thank the very patient editors who had to deal with switching the publisher and coming up with ways to improve the quality of my illustrations in my article about #stylometry in #French and #Spanish for #Picasso 's writings: @christof @josecalvo @u_henny and Robert Hesselbach, Daniel Schlör
The book is also available #OpenAccess online at #heiUP: https://heiup.uni-heidelberg.de/catalog/book/1157 and I would like to thank the very patient editors who had to deal with switching the publisher and coming up with ways to improve the quality of my illustrations in my article about #stylometry in #French and #Spanish for #Picasso 's writings: @christof @josecalvo @u_henny and Robert Hesselbach, Daniel Schlör


If you are interested in computational approaches to #Arabic and #stylometry, you can join us for two hybrid sessions at #DAVO2024 this afternoon with papers by Maxim Romanow (Hamburg), Maroussia Bednarkiewicz (Tübingen), Xenia Kudela (Berlin), Aslisho Qurboniev (London), and myself.
Zoom link: https://uni-goettingen.zoom-x.de/j/69656412607?pwd=a2bbBLdGKYJdyfl6PGlwNg8fdvPNXQ.1
New #paper out: « Code #stylometry vs formatting and minification » https://peerj.com/articles/cs-2142/ , where we show how much current code stylometry techniques (i.e., how to automatically detect the author of a source code snippet) are resistent to automatic code formatting and minification. (Spoiler: quite a bit, authors can still be identified after those source-to-source transformations.) Available #openaccess on #PeerJ CS.
Interesting! Dominika Weronska on "A Stylometric Glance at Basque Novels" at #DH2024. #stylometry
The author did stylometric analyses on 57 Basque novels, a first!
Now up at #DH2024, Maciej Eder, developer of #stylo and co-organizer of #DH2016 in #Krakow, on various distance measures for #Stylometry: "Manhattan, Euclidean and their Siblings. Exploring Exotic Measures of Text Similarities...".
Key idea: Manhattan distance is L1-norm based, Euclidean is L2. But we can vary this parameter for a wide range of values, from 0.1 to 10. Then evaluate accuracy for authorship attribution.
Result: For longer vectors, it pays off to use a value of less than 1!


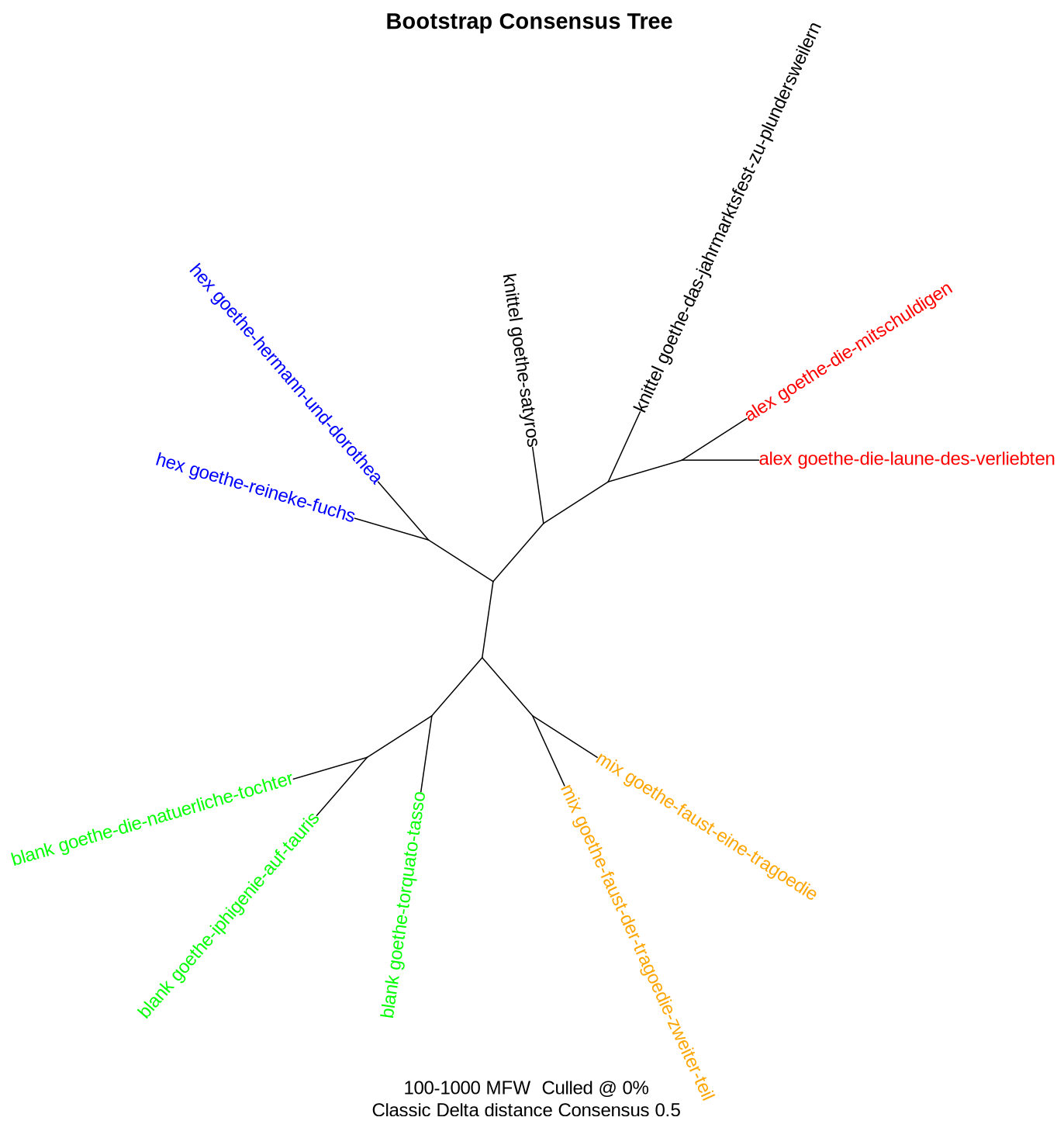
Kurz mal getestet, stylo() kann die verschiedenen Versformen bei Goethe ziemlich sicher auseinanderhalten: Dramen in Alexandrinern, Knitteln, Blankversen, gemischten Versen sowie die beiden hexametrischen Epen.
(Volltexte via #DraCor bzw. @gutenberg_org.)
@dvergano … until you start using techniques to defend against #stylometry
https://www.whonix.org/wiki/Stylometry
(One of the many reasons I love and support the #whonix project)
@jcls Another paper we would like to highlight, again for the lovers of #novels
Dorothy Henriette Modrall Sperling, Mike Kestemont & Vincent Neyt (2023), “The Authorship of Stephen King’s Books Written Under the Pseudonym “Richard #Bachman”: A Stylometric Analysis”, Journal of Computational Literary Studies 2(1), 1–35. doi: https://doi.org/10.48694/jcls.3594
Keywords: #Stephen_King, #stylometry, #pop_culture, #authorship verification, contemporary English-language #fiction

This next paper is about #stylometry in a #translation setting involving novels in #Swedish and #Danish:
Martje Wijers (2023), “Why the Daisy sisters are different. A stylometric study on the oeuvre of Swedish author Henning #Mankell and the Dutch translations of his work”, Journal of Computational Literary Studies 2 (1), 1–27. doi: https://doi.org/10.48694/jcls.3585
Keywords: #stylometry, #cluster analysis, #PCA, #delta, #zeta, #translation

A spontaneous Saturday afternoon provocation: "Dear fellow stylometrists, let’s drop the dendrogram and cherish the distance matrix": https://dragonfly.hypotheses.org/1414

Very happy to participate in today's workshop on "Potentials and Limits of #Stylometry for Early Modern Text in #Romance Languages". It's co-organized by the "Pamphlets and Patrons" #PAPA project in Early Modern French History and the Trier Center for Digital Humanities @tcdh today.
The programme is here: https://tcdh.uni-trier.de/en/event/hybrid-workshop-potentials-and-limits-stylometry-early-modern-text-romance-languages










