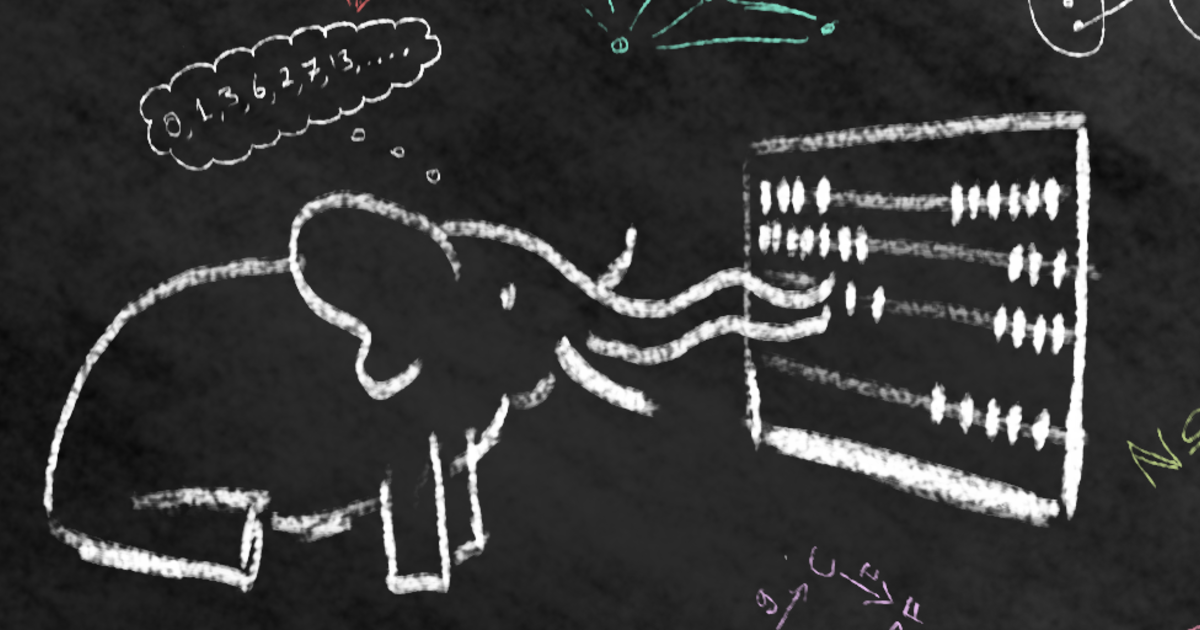
Andrew Lampinen<p>Research in mechanistic interpretability and neuroscience often relies on interpreting internal representations to understand systems, or manipulating representations to improve models. I gave a talk at the UniReps workshop at NeurIPS on a few challenges for this area, summary thread: 1/12<br><a href="https://sigmoid.social/tags/ai" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>ai</span></a> <a href="https://sigmoid.social/tags/ml" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>ml</span></a> <a href="https://sigmoid.social/tags/neuroscience" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>neuroscience</span></a> <a href="https://sigmoid.social/tags/computationalneuroscience" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>computationalneuroscience</span></a> <a href="https://sigmoid.social/tags/interpretability" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>interpretability</span></a> <a href="https://sigmoid.social/tags/NeuralRepresentations" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NeuralRepresentations</span></a> <a href="https://sigmoid.social/tags/neurips2023" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>neurips2023</span></a></p>
Recent searches
No recent searches
Search options
Only available when logged in.
mathstodon.xyz is one of the many independent Mastodon servers you can use to participate in the fediverse.
A Mastodon instance for maths people. We have LaTeX rendering in the web interface!
Administered by:
Server stats:
2.8Kactive users
mathstodon.xyz: About · Status · Profiles directory · Privacy policy
Mastodon: About · Get the app · Keyboard shortcuts · View source code · v4.3.7
#neuralrepresentations
0 posts · 0 participants · 0 posts today
Fabrizio Musacchio<p>How to measure (dis)similarity between <a href="https://sigmoid.social/tags/NeuralRepresentations" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NeuralRepresentations</span></a>? This work by Harvey et al. (2023) ( <span class="h-card" translate="no"><a href="https://sigmoid.social/@ahwilliams" class="u-url mention" rel="nofollow noopener noreferrer" target="_blank">@<span>ahwilliams</span></a></span> lab) illuminates the relation between <a href="https://sigmoid.social/tags/CanonicalCorrelationsAnalysis" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CanonicalCorrelationsAnalysis</span></a> (<a href="https://sigmoid.social/tags/CCA" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CCA</span></a>), shape distances, <a href="https://sigmoid.social/tags/RepresentationalSimilarityAnalysis" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>RepresentationalSimilarityAnalysis</span></a> (<a href="https://sigmoid.social/tags/RSA" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>RSA</span></a>), <a href="https://sigmoid.social/tags/CenteredKernelAlignment" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CenteredKernelAlignment</span></a> (<a href="https://sigmoid.social/tags/CKA" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CKA</span></a>), and <a href="https://sigmoid.social/tags/NormalizedBuresSimilarity" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NormalizedBuresSimilarity</span></a> (<a href="https://sigmoid.social/tags/NBS" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NBS</span></a>):</p><p>🌍 <a href="https://arxiv.org/abs/2311.11436" rel="nofollow noopener noreferrer" translate="no" target="_blank"><span class="invisible">https://</span><span class="">arxiv.org/abs/2311.11436</span><span class="invisible"></span></a></p><p><a href="https://sigmoid.social/tags/CompNeuro" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CompNeuro</span></a> <a href="https://sigmoid.social/tags/Neuroscience" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>Neuroscience</span></a> <a href="https://sigmoid.social/tags/NeurIPS2023" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NeurIPS2023</span></a></p>
Fabrizio Musacchio<p>Looking very much forward to the upcoming <a href="https://sigmoid.social/tags/iBehave" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>iBehave</span></a> seminar with Carsen Stringer ( <span class="h-card" translate="no"><a href="https://neuromatch.social/@computingnature" class="u-url mention" rel="nofollow noopener noreferrer" target="_blank">@<span>computingnature</span></a></span> ) on “Unsupervised pretraining of <a href="https://sigmoid.social/tags/NeuralRepresentations" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NeuralRepresentations</span></a> for <a href="https://sigmoid.social/tags/TaskLearning" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>TaskLearning</span></a>” 👌</p><p>⏰ October 06, 2023, at 12 pm<br>📍 online<br>🌏 <a href="https://ibehave.nrw/news-and-events/ibehave-seminar-series-talk-by-dr-carsen-stringer/" rel="nofollow noopener noreferrer" translate="no" target="_blank"><span class="invisible">https://</span><span class="ellipsis">ibehave.nrw/news-and-events/ib</span><span class="invisible">ehave-seminar-series-talk-by-dr-carsen-stringer/</span></a></p><p><a href="https://sigmoid.social/tags/Neuroscience" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>Neuroscience</span></a> <a href="https://sigmoid.social/tags/CompNeuro" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CompNeuro</span></a></p>
Fabrizio Musacchio<p>Looking forward to tomorrow’s 2nd workshop on <a href="https://sigmoid.social/tags/symmetry" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>symmetry</span></a>, invariance and <a href="https://sigmoid.social/tags/NeuralRepresentations" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>NeuralRepresentations</span></a> at the <a href="https://sigmoid.social/tags/BernsteinConference" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>BernsteinConference</span></a>: <a href="https://sigmoid.social/tags/GroupTheory" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>GroupTheory</span></a>, <a href="https://sigmoid.social/tags/manifolds" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>manifolds</span></a>, and <a href="https://sigmoid.social/tags/Euclidean" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>Euclidean</span></a> vs <a href="https://sigmoid.social/tags/nonEuclidean" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>nonEuclidean</span></a> <a href="https://sigmoid.social/tags/geometry" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>geometry</span></a> <a href="https://sigmoid.social/tags/perception" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>perception</span></a> … I’m pretty excited 🤟😊<br><a href="https://sigmoid.social/tags/CompNeuro" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>CompNeuro</span></a> <a href="https://sigmoid.social/tags/computationalneuroscience" class="mention hashtag" rel="nofollow noopener noreferrer" target="_blank">#<span>computationalneuroscience</span></a> </p><p>🌏 <a href="https://bernstein-network.de/bernstein-conference/program/satellite-workshops/neural-representations/" rel="nofollow noopener noreferrer" translate="no" target="_blank"><span class="invisible">https://</span><span class="ellipsis">bernstein-network.de/bernstein</span><span class="invisible">-conference/program/satellite-workshops/neural-representations/</span></a></p>
SearchLive feeds
Mastodon is the best way to keep up with what's happening.
Follow anyone across the fediverse and see it all in chronological order. No algorithms, ads, or clickbait in sight.
Create accountLoginDrag & drop to upload